Reference: http://www.codeproject.com/KB/architecture/NewApproachToDesignWebApp.aspx

Figure 1: Multi-tier app with isolated generated code
Introduction
With all the hay being made about UML modeling, you'd think that was the only way to design an application. I've got news for you. It's the wrong approach.
Now, before you flame me for my heresy, read the rest of this paragraph. Much like the 60% genetic similarity between the genes of humans and fruit flies, almost all web applications are identical. Except that I would put the commonality at closer to 75%-90%. And I challenge anyone who's developed more than two web applications to dispute this fact. Face it, almost all that most applications do is get data, do something to it, then put it back. There's even an acronym for these applications: CRUD (Create, Retrieve, Update, Delete). This, of course, begs the obvious quip "I've sure seen a lot of CRUDdy applications in my day," or "That application is CRUD!"
A New Way of Building
The current "best practice" for many companies is to build massive class diagrams with actors and use cases and different relationship mappings, then implement code from these diagrams and documents. The DBA is expected to build a database to back this theoretical framework. Simultaneously, the developers begin building objects to match the diagram. Theoretically, changes require change orders, model redesign, and wholesale throwing out of code to be rewritten.
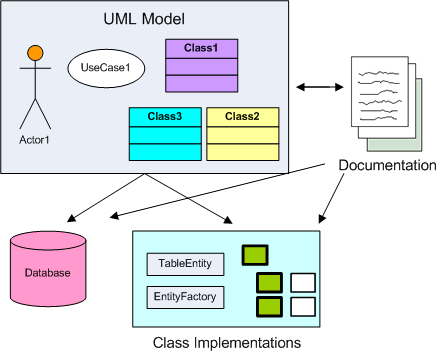
Figure 2: Traditional SDLC design-build flow
Within three days of building an actual software, these diagrams are hopelessly out of synch with the application. In two more weeks, these diagrams begin to rot in some document repository, never to be seen nor heard from again.
Aside: UML is not as bad as it seems I make it out to be. It can be very useful in understanding complex problems, but tends to be over-used for simple problem domains, and can actually result in a decrease in software quality. But documentation is a topic for another article.
What we need is a new way to build our applications. Instead of scattering the manual work and items requiring decision making across the development process, we need to do the "thinky" things first then automate the rest. Why don't we just stop doing things the hard way? Why not just build our database and run a code generator against it to spit out the basic entity objects and data access layer?
Enter Data First Development (I'll see if I can coin this here).
Data First Development (DFD)
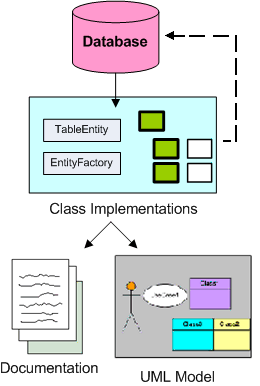
Figure 3: Data First Development
Data First Development (DFD) revolves around building your application from the bottom up. It is a method best suited for N-tier development by small teams or individual developers, but can be applied to larger teams. Much as how a house is built from the foundation up, DFD requires you to start with your application's foundation (database). A house begins with the foundation, then adds the walls, roof, and finally all the finish work and flushable toilet. DFD uses the database as the foundation, then builds the object model structure (walls and roof), and finally the UI (fixtures). Although, our metaphor would be more apt if your house's walls were built on casters or rails to safely shift and reconfigure rooms.
DFD is a not a full application life cycle development methodology. It is a nuts and bolts technique for stitching together existing tools and techniques to quickly and efficiently build a specific class of application: multi-tier, distributed, and data-backed - the most prolific type of which would be the data-driven web application.
In Data First Development, the database is designed and built first and quickly. It is better to build and begin developing against an 80% complete data model than to wait two more months for a 95% complete data model. No matter how good you are or how solid your requirements are, your data needs will change and evolve during development. These changes need to be exposed as soon as possible, and developing working code is the shortest path to exposing them. But don't be afraid - your generated code will save you from early missteps.
DFD Steps
- Build your database
- Generate your Entity/Factory code (and possibly UI framework)
- Subclass and extend as needed
- ...Iterate and repeat steps 1-3 as the design needs change
- Generate project documents
To be fully effective, this technique requires that you keep your generated code as isolated as possible from the rest of the application code. This includes designing the front end to be loosely coupled as well. A large precept of this methodology is to isolate your entity/data access tier so that it can be swapped out as the underlying data morphs, without affecting your main business logic or front end design and code interaction (see Figure 1 above). In the best case scenario, you view your generated code as a black box to be swapped out at will.
How is DFD new?
Now, I know all you true students of the art are gearing up arguments about how this is just MDA (Model Driven Architecture) and/or ORM (Object Role Modeling or Object Relation Mapping, depending on whom you ask) with some different terms. Well, maybe, somewhat, and no (not necessarily in that order).
MDA revolves around maintaining a core model of the software in an implementation-neutral format (like UML, which is what we're trying to get away from). DFD could make use of a neutral modeling format, but more likely you'll start with a specific implementation of one system aspect (the database), then generate your artifacts (code, tests, and documents) from that. Previous high end code generators, like Rational Rose (now owned by IBM), are designed to model and build from UML. Most of the newly emerging code generation tools that we make use of (open source and commercial) build code directly from a database.
Object Relation Mapping is a process of mapping the data fields of an existing object to a persistence store. This assumes an existing code object which must be mapped downwards to an existing database. This is the exact opposite of DFD, which is an upward generation of object code from only the database. Object Role Modeling, on the other hand, is a method for modeling complex interrelations and business logic. This is an abstraction layer above what DFD accomplishes and has much broader applications beyond what DFD can handle.
Choosing the Right Code Generator
You must use a code generator, both for quality reasons and to stave off carpal tunnel syndrome. Below, I'll outline some of the available options and some considerations to make when choosing. There is also a very good article by Rajesh Sadashivan on what resources and generators are currently available: ORM, Code Generation and a bit about MDA.
Topics we'll cover in the decisions section:
- Stored procedure support
- Project definition and tool scriptability
- Extensibility and Templates
- Language support
- ORM vs. Hard Coded
- Full application stub support
- Unit tests
To Build or Buy your Generator
The eternal question in software. Back in early 2000, when I started playing in this space, the answer was easy: Build.
I put together my first Entity/Factory code generator for VB6 in early 2000. Since then, I've build several versions for VB6, Java, J2EE, C#, and PHP. I even wrote a series of articles on the subject using CodeDOM and C#. I currently have several applications I maintain and enhance, so I have kept these various tools around, for better or worse.
Today the answer is somewhat different. In the last couple of years, there has literally been an explosion of tools for doing object mapping and code generation (or full application generation). Everyone seems to have had the same realization almost simultaneously: building N-tier applications is largely a repetitive task that a trained monkey could do and is more suited to code generators. Today, with the proliferation of code generation tools, only a fool or a control freak would write and maintain their own toolkit for this. Alas, I am that fool. But I digress.
Decisions, decisions, decisions
Buy or build, you'll have the same decisions to make. In the "buy" case, you're evaluating feature sets of an existing product. In the "build" case, you're designing your tool's capabilities. These are important questions to answer before you marry yourself to a tool.
Stored procedure support
How important is this to you? Stored procs help prevent SQL injection attacks by their parameterized nature, and are considerably faster than inline SQL statements (over 10x, I've heard). They can also be more difficult to maintain, expose some of your business logic to the client (albeit a trivial amount in most scenarios), and are not fully supported in all databases.
Project definition and tool scriptability
A one-off build is fine to do with a point and click interface. For multiple builds, you'll want a defined "Project" that encapsulates all the target tables/classes and any build options. For a really streamlined development environment, you'll want a tool that can be (gasp) command line driven. If you stick with the DFD principle of utilizing an isolated and fully generated black box entity object and data access layer, you'll want to automate this regeneration as part of your continuous integration process (possibly with CruiseControl and Ant/Nant). You are doing continuous integration, aren't you?
Extensibility and Templates
Will you need to modify the output code in the future? Like it or not, the answer is probably yes. Languages evolve and implement better features. Bugs are discovered. Optimizations need to be implemented. While one product might be able to tolerate a static design for the generated code, over several generations and several products, you will want the underlying generated code style to change.
Proprietary tools often generate the cleanest code, but you become married to them and reliant on them to update their tool. Open source allows for modification, but the cost of code customization is large; ditto for home grown systems. My advice is to find a good template-based solution with an active community around it and go through the learning curve on that tool.
Language support
Do you always build in <insert language> [C#|Java|Ruby|VB|PHP], or do you build different products in different languages? Most commercial products will support multiple languages, but only within a family (ex: C#, VB, and JScript). There are several tools that support both Java and the .NET language family.
Template-based solutions tend to have a broader range of language support, as well as better extensibility. MyGeneration seems to have the broadest range of language support and a healthy development community adding new templates and language support all the time.
If you build your own tool and are working with .NET, one option is to use the .NET CodeDOM classes. Theoretically, it means any language could be written as output, given an appropriate CodeDOM CodeProvider is written. Realistically, it means you can output only VB and C# code (and maybe J#, but no one uses that unless they want a zip library). The whole point of using different languages is to take advantage of language-specific features. No matter what the abstraction level, some languages just do things differently, so a code generation abstraction layer will never work beyond a given language family (ex: .NET languages). I found CodeDOM ugly and difficult to implement with, as well as adding 500% code bloat to my generator.
Object Relation Mapping vs. Hard Coded
Mapping-based frameworks allow runtime mapping of database columns to object properties, usually via an XML mapping file. These tools are convenient and flexible. They don't always have generators, but it should be trivial to write a tool to output the entity class and XML mapping file. That said, I would advise against anything that involves runtime mapping. It is going to be late-bound and suffer a serious performance penalty as a result. Better to use a tool providing hard-coding and early binding. The flexibility is not worth the cost.
Mapping based frameworks
Full application stub development
Several of the more sophisticated tools can go far beyond generating an object-data access layer. Some of them can build full fledged user interfaces as well. This can save considerable time if you tend to do very direct CRUD applications. A fully generated application can be quite adequate for many of the internal projects company IT shops are asked to develop. I typically view the UI generated by these tools as a convenient starting point at best, and will only generate the front-end code once, to be hand modified from there.
Unit tests
MyGeneration is the only tool I know of, that even touches on auto-generation of unit tests. Do not deny the importance of unit tests. Feel the power of unit tests! You cannot hope to control unit tests, you can only hope to contain them! There is no reason your basic tests cannot also be auto-generated, although more substantive tests will be hand coded, especially if you are doing TDD (Test Driven Development).
Most unit test code you encounter will be targeted towards NUnit, but I consider CSUnit superior due to its Visual Studio integration. It may all be a moot point since VS 2005 has a unit test framework built in.
Back Filling Documentation
I'll leave my full discussion on documentation for another article (in the works), but I do want to touch on it.
Traditional SDLC dictates that all code is designed and documented prior to implementation. As anyone who has worked on a full life cycle release will tell you, this model goes out the window as soon as the team starts writing code. In strict SDLC process environments, it is not uncommon for teams to spend almost as much time updating specs as writing code. And the two are never in sync.
Much in the same way our code object model is built up from the data structure, much of the documentation can be built up from the code. The proof, as they say, is in the pudding, and documents generated from functional code is less likely to lie.
The Java camp was the first (that I'm aware of) which formalized a process for building documentation from code (i.e. Javadoc). Microsoft followed suit in their own way, but the built-in tools leave something to be desired. You will need some sort of add-on tool to complete the job. There are also some decent UML diagram reverse engineering tools, but many of the best ones are only available for the Java camp.
- NDoc
- Article: Documentation in C#, by Jaiprakash M Bankolli
- Visio reverse engineering (which does a poor job of UML generation)
Summary
Boy, this got to be a wordy article! For brevity, I'll outline my actual/ideal tools and methods for doing Data First Development (DFD) in a short few steps.
Step By Step
This describes building an MS stack application, with C# for the code and MS SQL Server for the back end, but you can extrapolate as needed. Anything with [ideal] means I'm running a team of devs and/or someone else is paying for my tools.
Step 0: Have some idea of what you're building
External to this process, I start with enough product requirements to begin the implementation of the system. Look up Scrum if you want my preferred technique of getting and managing product requirements.
Tools
- Someone with a product vision and/or money burning a hole in their pocket [ideal].
Step 1: Build the Database
Data tables and relationships only.
Tools
- Microsoft SQL Server Enterprise Manager (table building GUI and diagram tool).
- ER/Win [ideal]. (Who knew CA bought them? Product will probably suck in < 3 years.)
Step 2: Generate Object Model Code
Use the selected code generation tool to build out entity and factory classes, as well as stored procedures and preliminary unit tests. Package the end product code (entity/factory classes) in a separate DLL.
Tools
- Custom code generator
- MyGeneration
- Iron Speed [ideal]
Step 3: Build Custom Business Logic
Subclass your generated code any time you want to tweak it. This insulates you from having your custom code stomped on if you have to regenerate things. I actually like to keep the core code regeneration in my autobuild/continuous integration process. Part of this process is also building and running a reasonable number of unit tests.
Tools
- Whatever IDE is appropriate (Visual Studio, in this example).
- Under-paid CompSci intern for while I'm on vacation in Mexico [ideal].
- CruiseControl.Net
- Nant
- CSUnit
Step 4: Generate Project Documentation
Early stage documents are useful in defining the scope and needs of the application, but seldom much else. Maintaining formal documents during development is an anchor and may delay shipping the product. If required, I'll generate documents after the project is finished or ready to ship (because when is a work of art ever really finished). This is essentially the same approach I took to writing term paper outlines in school.
Tools
- NDoc
- (once again) Under-paid CompSci intern for while I'm on vacation in Mexico [ideal].
In most cases, steps 1 (database build) and 2 (code generation) will loop during step 3 (custom coding). The whole point of this approach is to reduce repetitious coding and insulate the product and yourself from mid-development requirements changes.
Conclusion
Over the years, the industry's understanding of building multi-tier distributed applications has continued to evolve. The technique outlined here is evolutionary rather than revolutionary. The explosion of code generators following this "build from database" approach is a testament to how effective this technique is and how popular it has become.
As we streamline the more mundane tasks, more time and energy can be dedicated to creating innovative products than on plumbing code. Data First Development (DFD) is a technique that attempts to formalize the process of using all the fantastic new code generators out there to streamline development and improve the overall quality and speed with which you can deliver N-tier applications.
Even if you continue to do model and document driven development, seriously consider using a code generator. Your overall product quality will be greatly improved.
No comments:
Post a Comment